Here are the fruits of a mini-seminar on git from the inimitable Mary—a sketchy portrait of the inner workings of git.
Git: The Bestest Version Control System with the Worstest UI
All of your Git-age lives in the .git folder
When you run git init, all it does is create a .git folder. That’s it! Your machine knows what folders are and aren’t git repos by the presence or absence of a .git directory. .git is a hidden folder, so to see it, type ls -a. Whenever you add or commit things to your git repo, they’ll get stored in here.
I’m now in the directory of my new project, gittest. It contains two files, a and b, and isn’t yet a git repo. When I look at what’s inside it, it looks like this:
maia$ ls -a
. .. a b
Let’s make it a git repo:
maia$ git init
Initialized empty Git repository in [stuff]/gittest/.git/
maia$ ls -a
. .. .git a b
We can see the .git folder! Success! Here’s the stuff inside it:
maia$ ls -a
. HEAD description info refs
.. config hooks objects
Anatomy of a commit: blobs, trees, commits
The git magic happens largely in the /objects folder. Right now it’s got two folders in it that we don’t care about, info and pack, which have to do with misc. git magic. But this is where stuff goes when we add/commit it. So let’s do that.
maia$ git add -A
maia$ ls .git/objects/
31 e9 info pack
31 and e9 are both folders, and each has only one object in it, files with big long gibberish names: 31/e9dce72edaeb87f2b007b09230bfd5008da63e and e9/1ace6ef46e2244fc3588bdead8f66b35b20d12. They contain gibberish, which is fancy git compression/encoding of the contents of file a and b. The folder name and file name, taken together, make a big long hash that you can use to recover the original file contents1 (xx/yyyyyy —> the hash xxyyyyyy):
maia$ glook e91ace6ef46e2244fc3588bdead8f66b35b20d12
stuff inside file a
These big long hashes point to files, known in git-land as blobs. Right now these are staged. After we commit them, .git/objects looks like this:
maia$ ls .git/objects/
31 81 a7 e9 info pack
We have two new directories in here since our commit, both in the same xx/yyyyyy format where xxyyyyyy is a big long hash thing we can use to access the thing inside. Here’s the stuff inside the two new things:
maia$ glook 81ad97f6d112d96081fffc3d3b729828917eff5e
tree a720b6d097b88601c3647be863269539ccc7f64d
author maianess <[email protected]> 1409698376 -0400
committer maianess <[email protected]> 1409698376 -0400
first commit
maia$ glook a720b6d097b88601c3647be863269539ccc7f64d
100644 blob e91ace6ef46e2244fc3588bdead8f66b35b20d12 a
100644 blob 31e9dce72edaeb87f2b007b09230bfd5008da63e b
The first thing is a commit object. It lists a tree object, author, committer, and commit message (which here is “first commit”). The second thing is a tree object: it contains references to all files or folders (which would also be tree objects) in the given commit. This tree points to our files a and b (identified by their magic git hashes).
OH, but also, from the second commit onward, commit objects look a little different. They have one additional line that provides the hash of the parent, or the commit directly before that one. I added a file c in directory foo. Here’s what my second commit looks like:
maia$ glook 33380bb5dfd152bf72dad49c3e388bccee1a4dfb
tree 0d656c0ff73ea5315ec498acf144df9958e48819
parent 81ad97f6d112d96081fffc3d3b729828917eff5e
author maianess <[email protected]> 1409709920 -0400
committer maianess <[email protected]> 1409709920 -0400
second: added directory 'foo'
To sumarize, the three kinds of objects you’ll find in .git/objects look like this.
#####Blob, aka file: [encoded contents of the file]
#####Commit:
tree: [hash of tree pointing to the files of this commit]
author: [name]
[commit message]
#####Tree:
[hash of a blog (file)]
[hash of a blog (file)]
[hash of a blog (file)]
…as many times as you want
[hash of a tree (folder)]
[hash of a tree (folder)]
…as many times as you want
####How a few commits might look Git objects contain the hashes of other git objects, which is how the files keep track of each other. Given a commit, you can find the tree representing the root, and from there all of the files and/or folders (represented by trees) that it contains. From that same commit, you can also find it’s parent commit, and then its parent, each with their attendant file-states, and so can trace your history back. Let’s look at fun diagrams!
Here’s my initial commit, when the file tree looks like this, and my git looks like this:
.
├── a
├── b
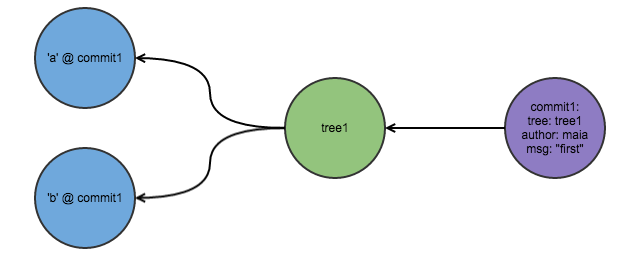
Now let’s say I add a directory foo, and a file in foo c, and make changes to a and b. The file tree now looks like this, and my git looks like this:
.
├── a
├── b
└── foo
└── c
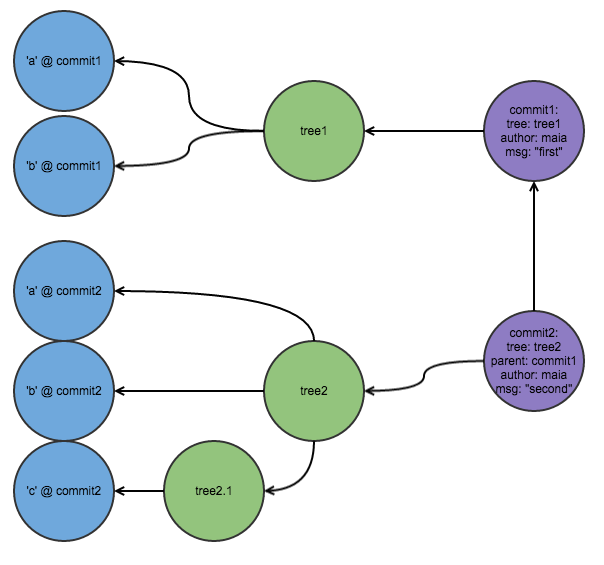
You see that the main tree, tree2, is pointing directly to a and b but not to c—rather, it points to tree2.1, which points to c. It looks this way because git uses trees to represent directories; it references files living in subdirectories via trees (representing those directories) referencing those files.
Note that git is still storing (in super-compact encoded form) all previous versions of the files, and given this network of things-that-contain-hashes-of-other-things, we know exactly where to look for any version of any file we want to find. And git only makes the necessary changes. Look what happens if we change a and c but leave b the same:
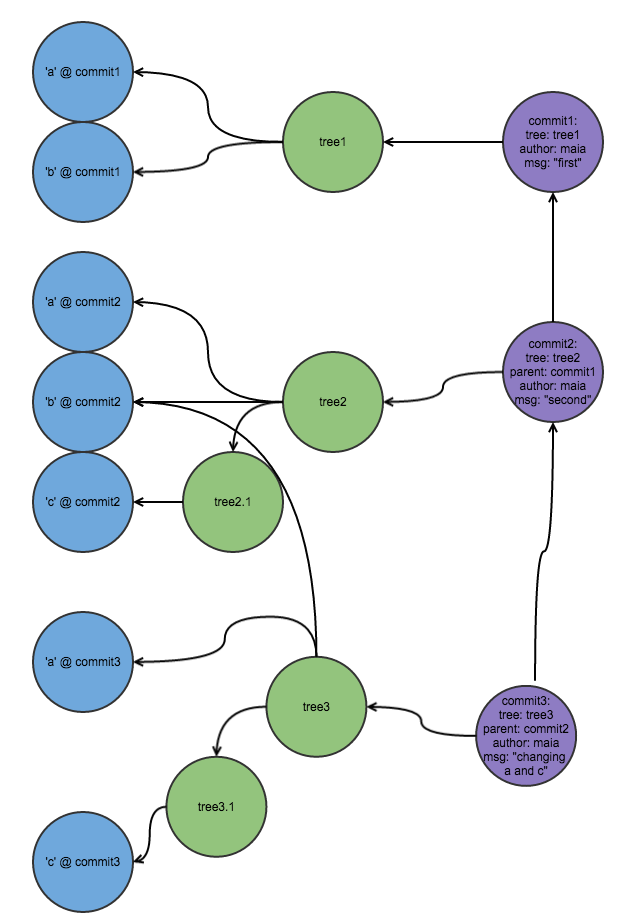
There’s no need to make another representation of b, since b hasn’t been changed this commit. Instead, where the tree has to point to b, it points to the hash of the existing version of b.
So, now I understand a biiiiit more about the whacky world of git and just what these cryptic commands are doing! I even understand pointers and branching and detached head state and all that a bit better, but that is perhaps another post for another day. Cheers!
-
glookis a shortcut I made; the full command to get file contents from one of these hashes isgit cat-file -p. ↩